This is a short summary of our paper “Leveraging Synthetically Generated Data for Real Estate Document Classification” by Tobias Deußer, Gregor Ramien, Nico Weber, Maximilian Meidinger, Max Hahnbück, Christian Bauckhage, and Rafet Sifa, published in the proceedings of the 2025 IEEE International Conference on Big Data. See here for the published version and here for the open-access bonndoc version.
Document classification in regulated industries like real estate and banking is hindered by a fundamental tension: the models that could automate workflows require large amounts of labeled training data, yet the sensitive nature of the documents makes collecting and annotating real examples difficult or legally fraught. In this work, we address this challenge by building a pipeline that generates realistic synthetic training data without ever exposing real documents.
Our focus is on two document types central to German mortgage financing workflows: the Nachweis Kindergeld (Child Support Certificate) and the Individueller Sanierungsfahrplan (Refurbishment Roadmap). Rather than collecting and anonymizing real examples, we construct Jinja-based templates derived from manual analysis of genuine documents and populate them with a combination of rule-based (Faker library) and LLM-generated content. A third catch-all class, Sonstige (“Other”), is generated entirely by prompting an LLM with a diverse set of everyday document types to serve as a realistic negative class.
The pipeline proceeds as follows:
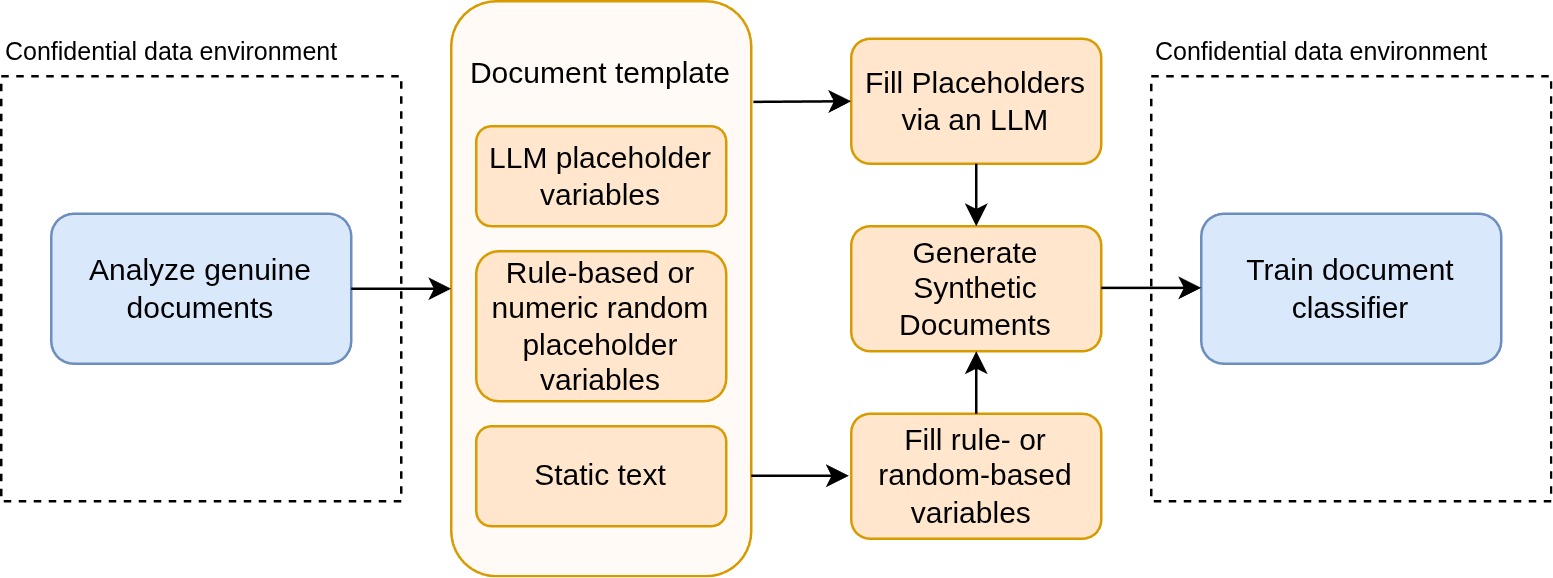 Figure 1: The complete data synthesizing and training pipeline for our document classifier.
Figure 1: The complete data synthesizing and training pipeline for our document classifier.
- Template Design: Real documents are analyzed manually to extract layout patterns, static text, and variable fields.
- Placeholder Filling: Simple fields (names, dates, addresses) are filled via the Faker library; semantically rich fields are filled by an LLM to preserve document coherence.
- Augmentation: Documents can be reordered, rephrased, or degraded with synthetic OCR noise to increase variation.
- Classifier Training: A BERT-based encoder with a linear classification head is fine-tuned on the resulting synthetic pages.
We evaluate the trained classifier on a manually annotated real-world test set of 52 documents (240 pages), compiled by domain experts, the model never saw any real documents during training. The composition of this test set is shown below:
| Category | # Pages | # Documents |
|---|---|---|
| Empty Page | 4 | 2 |
| Child Support Certificate | 53 | 32 |
| Refurbishment Roadmap | 120 | 12 |
| Other | 63 | 6 |
| Total | 240 | 52 |
Key Results:
- Basic 3-class setup: Page-wise average precision of 88.3%, demonstrating strong zero-shot-to-real-world transfer.
- Fine-grained 15-class setup (each page template as a distinct class): Page-wise AP of 81.4%, showing the approach scales to more granular classification.
- Reduced template scenario (75% of Refurbishment Roadmap templates): AP of 80.8%, confirming that competitive performance can be achieved even with incomplete template coverage, thus reducing manual effort.
The main limitation is that template creation remains manual and time-consuming, and synthetic data may not fully capture the long-tail variability of real-world documents. Future work will target fully automated template generation using structure-aware LLMs, extension to layout-aware models, and broadening the approach to information extraction tasks beyond classification.