This is a short summary of our paper “Towards Reliable Machine Translation: Scaling LLMs for Critical Error Detection and Safety” by Muskaan Chopra, Lorenz Sparrenberg, and Rafet Sifa, published in the proceedings of ECIR 2026. See here for the published version and here for the open-access Fraunhofer Publica version.
Machine translation plays a major role in multilingual information access. It supports public communication, cross-lingual search, professional workflows, and everyday digital assistance. But when translations contain critical meaning errors, the consequences can be serious: wrong medical advice, distorted legal meaning, incorrect financial information, or biased public communication.
This paper studies whether instruction-tuned LLMs can act as safeguards by detecting such critical translation errors.
We frame Critical Error Detection as a binary task: given an English source sentence and a German translation, the model must decide whether the translation contains a meaning-critical error or preserves the intended meaning. We compare encoder-only baselines such as BERT, ModernBERT, mmBERT, and XLM-R with decoder LLMs including GPT-4o, GPT-4o-mini, LLaMA, and GPT-OSS models.
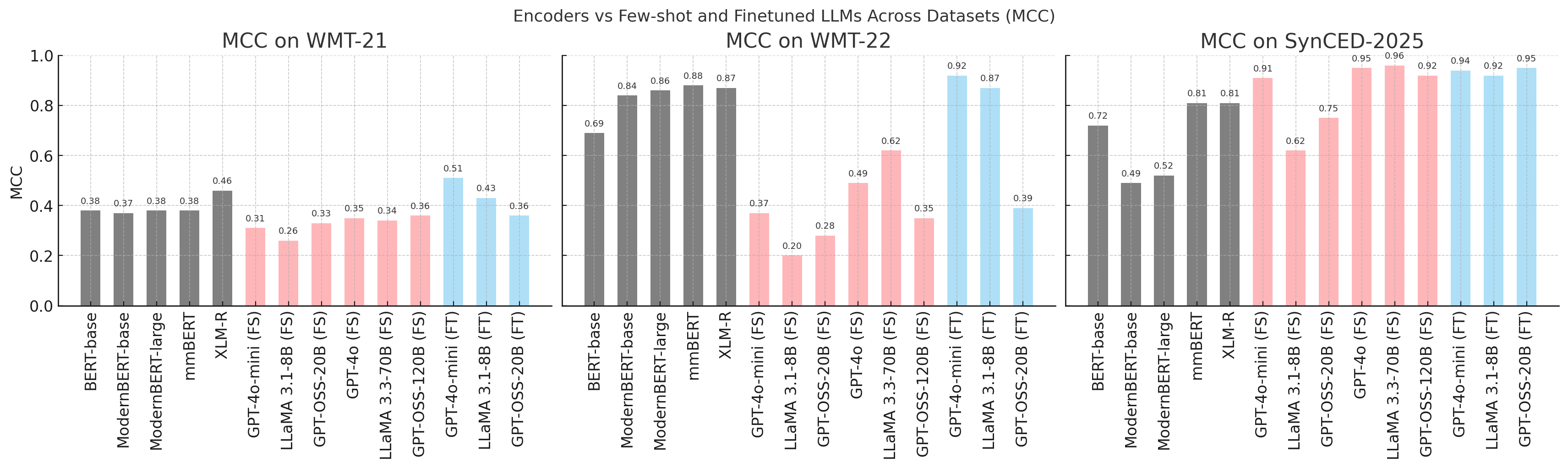
The experiments cover zero-shot prompting, few-shot prompting, tuned prompts, committee voting, and fine-tuning. The results show that scaling and instruction alignment improve sensitivity to critical errors, and that fine-tuned decoder models can outperform strong encoder-only baselines across WMT21, WMT22, and SynCED-EnDe 2025.
The broader point is that CED should not be viewed only as a technical benchmark. It is a practical safety layer for multilingual information systems, especially when translations are used in contexts where factual accuracy, fairness, and trust matter.